About
I'm a recent MTech graduate from IIT Guwahati with one year hands-on experience as a Data Science Trainee at iNeuron. Eager to apply my analytical and technical skills, I'm seeking roles in Data Analysis, Data Science, Data Engineering, Business Analyst or Bioinformatics. Motivated, enthusiastic, and open to opportunities, I bring a strong foundation in Data Science and a commitment to excellence. Let's connect and explore how I can contribute to your team.
Skills
NLP
- LSTM, BERT, GPT2, Google FLAN-T5
Generative AI
- LangChain, ChromaDb, FAISS, Google PaLM, OpenAI GPT
Computer Vision DL
- Classification, Detection, Segmentation, Tracking
MachineLearning DeepLearning & Generative AI






Database & Analytics




Visualization & Processing




Development & Deployment


AIOPS/ MLOPS



Automation



Programming

Tools



Resume
Education
Master of Technology In Biotechnology
2020 - 2022
Indian Institute of Technology, Guwahati, India
Bachelor of Technology In Biotechnology
2016 - 2020
Dr A. P. J. Abdul Kalam Technical University, Lucknow, Uttar Pradesh, India
National Level Examination
BET: Biotechnology Eligibility Test (DBT JRF)
2021
Conducted By Department of Biotechnology, Ministry of Science & Technology, Government of India to grant fellowships to candidates who want to pursue a Ph. D. in biotechnology
- Category - I
GATE: Graduate Aptitude Test in Engineering
Decipline: Biotechnology
2020
- Rank: 497
- Score: 515
UPSEE: Uttar Pradesh State Entrance Examination
Decipline: Biotechnology and B.Pharma
2016
- Rank (Biotech): 608
- Rank (B.Pharma): 400
Relevant Courses
Biostatistics
BTech | AKTU
Quantitative Biology
MTech | IIT Guwahati
Experience
Data Scientist
Feb 2024 - Present
Ministry of Rural Development
Skills: Python, Deep Learning for computer vision, FastAI, Data Analysis
Data Science Trainee
Sep 2022 - Sep 2023
PW Skills (Formerly: iNeuron.ai)
Skills: Python, Machine Learnig, Deep Learning For Computer vision, SQL, MongoDB, Excel, Tableau, Power BI, MLOPs, Git, Docker, Linux
Teaching Assistant
Feb 2022 - Jun 2022
Indian Institute of Technology, Guwahati, India
Performed TA duties
Summer Research Trainee
Jun 2018 - Jul 2018
MRD LifeSciences Pvt Ltd, Lucknow
Skills: PCR, SDS-PAGE, Protein, DNA and RNA Isolation, Western Blotting, Antibiotic Sensitivity Test, Cloning, Minimal Inhibitory Concentration Test, Antibiotic Sensetivity Test
Training
Full Stack Data Science
01 YEAR | Ongoing | iNeuron- PW Skills
- Python Programming
- Machine Learning
- Deep Learning | Computer Vision
Applied Data Science With Python Specialization
20 Weeks | Michigan University- Coursera
Five courses included
- Applied Plotting, Charting & Data Representation
- Applied Machine Learning In Python
- Applied Text Mining In Python
- Applied Social Network Analysis In Python
Data Science & Machine Learning
8 Weeks | Consulting & Analytics Club, IIT Guwahati
Excel For Data Analytics and Data Visualization
14 Weeks | Macquarie University- Coursera
Three courses included
- Excel Fundamentals For Data Analysis
- Data Visualization in Excel
- Excel Power Tools For Data Analysis
Skills: Power Query, Power Pivot, Power BI
Portfolio
Computer Vision | Deep Learning
This project involves 3D segmentation of brain tumors from the BraTS2020 dataset
using TensorFlow and 3D-UNET architecture. The BraTS2020 dataset is
approximately 40 GB in size, comprising both training (~30 GB) and validation sets (~10 GB).
The BraTS2020 dataset provides multimodal brain scans in NIFTI format (.nii.gz), which is commonly used in
medical
imaging to store brain imaging data obtained using MRI.
This project aims to detect the presence of coccidiosis, a common parasitic disease
in
Poultry(Chickens), using deep learning techniques. I have utilized transfer learning approach with the
VGG16
architecture to classify input fecal images as either indicative of coccidiosis or not
The project offers a comprehensive solution for object detection or segmentation using YOLOv8,
enabling precise localization and delineation of objects. It incorporates DeepSORT for object tracking
with unique IDs, facilitating continuous monitoring and providing visual tracking trails for object movement analysis.
The system uses computer vision techniques to prevent spoofing attempts during
face recognition, ensuring the accuracy and security of attendance records. Features Include Real-time face recognition
using the face-recognition Python library, Integration of the Silent-Face-Anti-Spoofing model for enhanced security.
User-friendly graphical user interface (GUI) created using the tkinter library.
Machine Learning
Launch
Thyroid diseases, such as hyperthyroidism and hypothyroidism, affect a significant
portion of the population and can
lead to serious health complications.In this project, I developed a machine learning-based multiclass
classification model to predict the likelihood of a patient having
a diseased state of the thyroid. Performed missing value handling, outlier handling, feature selection. 30
independent features,
15 class lables are present in original dataset. Class label of interest with miminum share makes 0.021%
and with maximum share is 4.87% in original data.
Score cards on Dshboard UI display LIVE SCORES for F1, ROC AUC, Balanced Accuracy and log loss. From
dashboard, user can view Data Profiling Report, EDA Report, Drift Report, Model Performance Reports, logs,
all artifacts and deployed model.
It also alow user to view and modify configuration and retrain model from dashboard itself.
I developed a web application for predicting forest fires (classification) and FWI-
Fire Weather Index (regression) using machine learning techniques.
The dataset had high multicollinearity among important features such as Fine Fuel Moisture Code (FFMC),
Drought Code (DC), Initial Spread Index (ISI),
and Fire Weather Index (FWI). To address this issue, I performed feature selection and feature engineering
techniques to reduce multicollinearity,
trained and evaluated different models including Random Forest, Gradient Boosting Trees, LightGBM, Support
Vector Regressor, and AdaBoost.
I utilized the ensemble technique of Voting Classifier and Voting Regressor in scikit-learn to produce
final predictors.
These ensembled models were used in the final Flask web application and deployed on Render.
The web app for making predictions about earnings is built using a Bagging
Classifier, which has outperformed other algorithms in our testing. The model was trained and tested using
the US Adult Census dataset from 1994.
"I developed a model for predicting spam emails and SMS messages using a combination
of Multinomial Naive Bayes and Bernoulli Naive Bayes.
The model was able to accurately identify spam messages in most cases, with the exception of messages
containing numerical values written in alphabetical form.
In such cases, the Bernoulli Naive Bayes algorithm performed better. Additionally, the model was able to
accurately identify legitimate emails from banks,
stock brokers, and other investment partners, avoiding the potential for important messages to be flagged
as spam.
The final model is able to predict one of three categories: 'Spam', 'Not Spam', or 'Others: Be cautious'
for emails that may require further scrutiny."
As part of my MTech thesis, As part of my MTech thesis, I completed a
project that
utilized Gradient Boosting algorithms to
identify DNA and protein backbones based on their backbone coordinates. Utilizing data from the PDB
database, I
extracted PDB files
and extracted the coordinates of key atoms, including P, O5, C5, C4, C3, O3 for DNA and N, C-alpha, C for
proteins for
the training of model.
Natural Language Processing & Generative AI
Text summarization is a crucial task in natural language processing and information
retrieval.
This project demonstrates the implementation of a Transformer-based model for generating concise and
coherent
summaries from longer text documents.
This is an end to end LLM project based on Google Palm, Langchain,
ChromaDB. We are building a system that can talk (Query in Natural Language) to MySQL database.
User asks questions in a natural language and the system generates answers by converting those
questions to an SQL query and then executing that query on MySQL database.
Powered by OpenAI GPT, LangChain, FAISS. this tool lets you dump URLs and ask questions about them.
You may ask for summarization or may ask other questions to get insights from the articles.
Python Programming
Launch
Developed webapp for calculating torsion angles and plotting Ramachandran Plots. It
uses
Biopython
for scrapping protein PDB files (PDB files store atomic cordinates for 3D structure of protein
macromolecules) and
Plotly for Plotting
Ramachandran Plots. It is fully automated app which allow user to upload PDB files or to just provide list
of PDB ID
(which is unique identifier for each file),
and to visualize full protein molecule or each chain of the molecule separately or to choose amino acids
to be
displayed on plot.
Apart from it, the app generate fully interactive plot as well as table of calculated angles which can be
downloaded
by the user.
Scrapyy is a web application that allows users to scrape data from Amazon.in and
store it in a
MongoDB database. Scrapyy is based on BeautifulSoup and generates two types of dataframes:
- Detailed DataFrame: Product Category, ProductID, ProductName, Rating, Number of customers rated, Discounted Price, DiscountPercentage and Actual Price
- Reviews DataFrame: Product Category, ProductID, ProductName, Customer Name and Reviews
Developed an image scraper for scraping images using Google Chrome (chrome Driver).
In this
projects I have used Selenium for automating the process. Here
user is allowed to search for the image of his/her interest and can mention number of images he/she wants.
Also, all
the images for a given query
will be stored in a single folder the name of query.
PowerBI
Demo
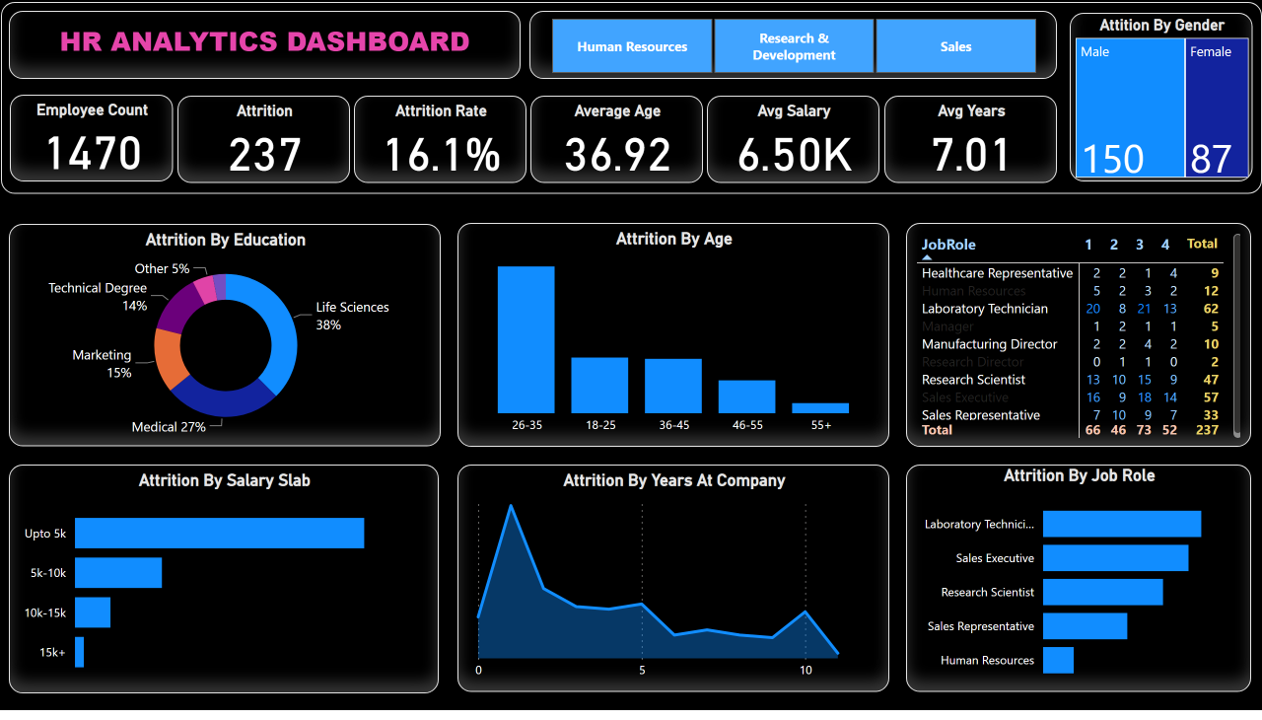
Performed data transformation, cleaning, conditional columns and measure in power
query and
build full working
HR analytics dashboard that shows differnt aspects for Attrition analysis. Final cleaned and transformed
data have
shape of (1470 rows, 37 cols).
Demo
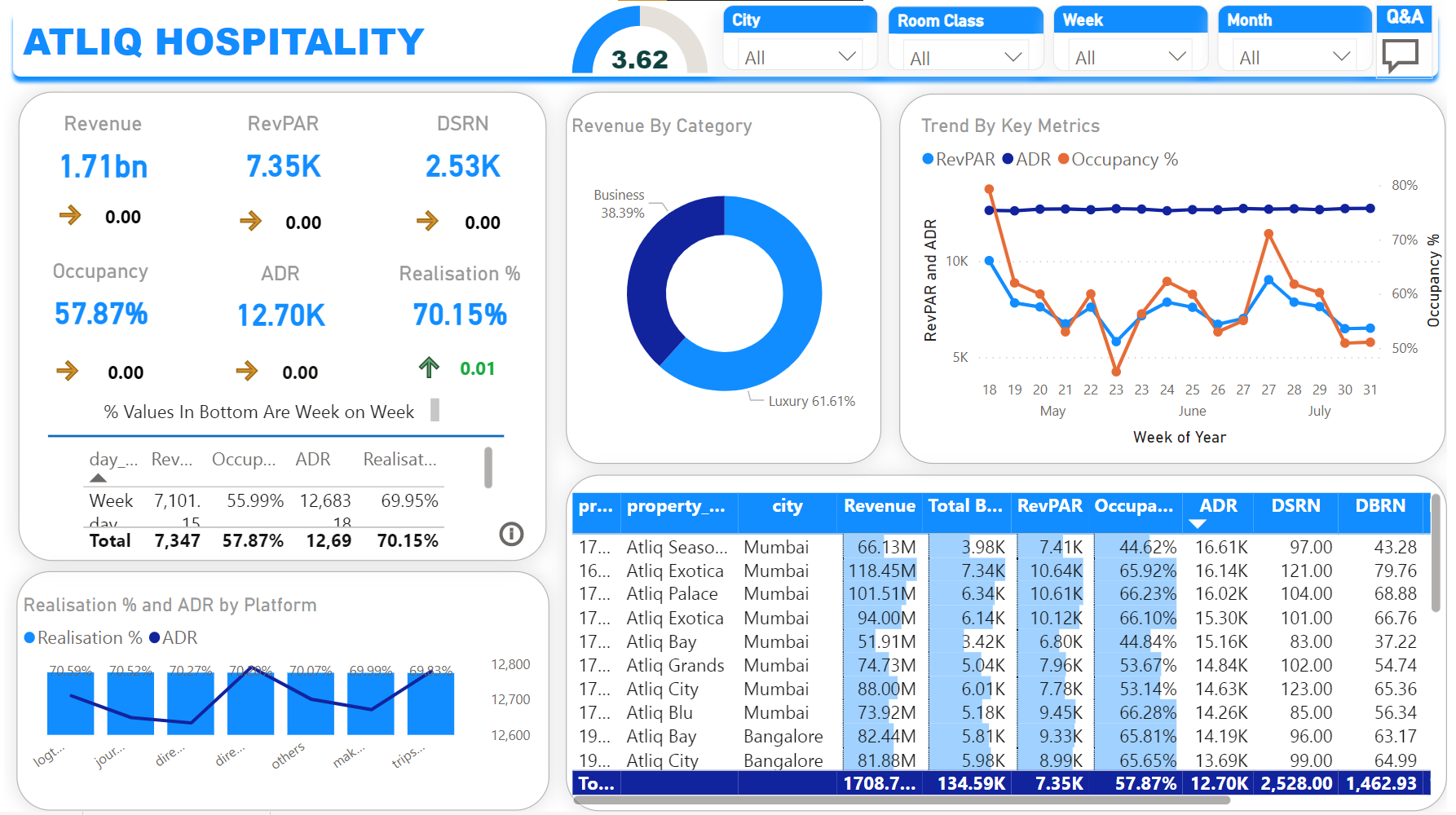
Performed data transformation, cleaning, conditional columns and measure in power
query and
build full working dashboard for revenue and analytics
for Atliq Hotels.
SQL
In this mini project, I performed an analysis of a music store dataset. I designed an Entity-Relationship (EER) diagram to visualize the relationships between the different tables. To improve code organization and reusability, I implemented stored procedures in MySQL. Additionally, I developed a Python script that efficiently pushed data into the MySQL database.